




Big Data—these two words are on everyone’s lips. Big Data is expected to be the answer to the problems faced by decision-support systems. Some even say that Big Data will replace Business Intelligence.
Together, let’s look at how Business Intelligence (BI) and Big Data are alike or differ on the famous 3 Vs that characterise Big Data: Volume, Velocity and Variety.
In terms of architecture, a very similar location
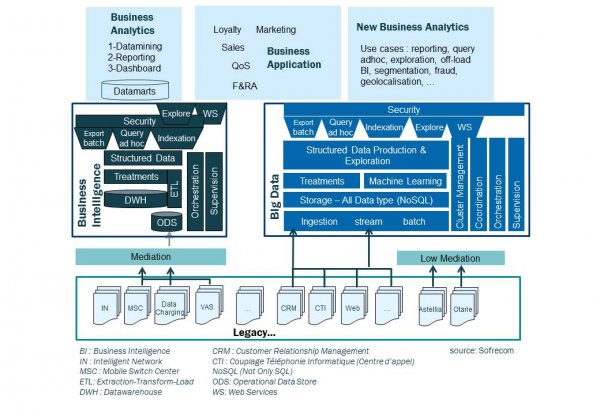
The similarities are shown in this overall architecture diagram:
- firstly, their positioning between the data source systems and the visualisation or analysis layers;
- also we find the concepts of collection, storage, processing and orchestration in both cases
The “Velocity” advantage of Big Data depends, in part, on the architecture of the BI
Business Intelligence traditionally presents D+1 indicators calculated the night before. On the other side, Big Data promises a velocity and processing capabilities, thanks to parallelization, that make real-time processing possible.
Looking at it from this perspective, there is no contest.
However, upon reflection, nothing prevents the BI extraction process (Extract, Transform, Load, or ‘ETL’) from being carried out in a faster cycle.
But are the sources that provide the data upstream capable of exporting it faster? Not always. In fact, as we were aiming for daily indicators, and for ease of integration, we have preferred to set up these processes in batch mode, most often at night, although aggregation over time would be possible.
Big Data does not always require velocity
We can also ask whether it is appropriate to want all indicators to be available instantaneously or to display a real-time status.
BI projects take a long time to implement. Indeed, ensuring data quality, accurate calculation and comprehensiveness at a desired aggregation level, all in order to carry out complex analyses, requires a number of tasks, audits and tests that cannot be reduced.
Redoing all these analyses through Big Data would also take a long time and would require new skills that are currently difficult to find.
It is therefore necessary to accurately assess the need for velocity before investing in a project to transform BI into Big Data.
At a certain volume of data, the only economically viable solution is Big Data
However, in the case of a BI solution that can no longer cope with a large volume of processing on large volumes of data, even over the course of a few hours at night, Big Data would then be the obvious solution.
In such a situation, BI solution providers suggest upgrading equipment to increase computing power. Along with this comes an increase in license costs (Database, ETL, etc.), which generally become prohibitively high.
Big Data then effectively presents itself as a suitable alternative.
Managing larger volumes is the very essence of Big Data: many of the logos in the world of Hadoop, such as Hortonworks, Hadoop and Hive, represent an elephant as a symbol of robustness.
Hadoop allows much greater volumes of data to be managed by distributing storage to standard-sized servers using parallel processing and enabling linear scalability. This is a real improvement compared to the scalability by fixed increments that is standard with BI servers.
From the point of view of storage, the combination of parallel processing, open-source software and standard equipment avoids a strong dependence on traditional BI solution providers.
Implementation again requires skills that are currently scarce, but these skills should eventually become more readily available.
Lastly, as Big Data solutions are based on open-source software, they suffer less from these additional license costs. There are distributors such as Hortonworks or Cloudera who offer industry-specific packages and related support subject to licences. However, they remain offered at much lower prices than BI solutions.
The unlimited volume of Big Data storage is just an illusion
Big Data’s high storage capacity gives the impression that everything can be kept indefinitely. We used to be careful: we established what data was necessary beforehand, and we only kept data that was essential.
With Big Data, we can abandon this approach and store data without prejudging the future data processing or possibilities. Business units believe that they are free from the cumbersome implementation of a new data acquisition process and that they can reduce their dependence on IT. But will all this data ever be used? Probably not.
From this point of view, we can store more data and we can store it for longer, but doing so generates costs that can be significant in the long term. Consequently, a storage management strategy remains necessary.
The “Variety” promise
Business Intelligence essentially consists of generating indicators and calculated data, based on structured data. The storage of unstructured data leads to the emergence of new uses. These open the door to new practices. It is thus unreasonable to try to twist BI solutions to fit these new uses when new, more efficient and more suitable technologies perfectly meet their needs.
This in no way diminishes the suitability and effectiveness of BI for traditional uses.
In conclusion
Thanks to Big Data technologies, we can collect larger volumes of data and we can do so much faster. We can store it for longer. However, despite the open-source approach, the infrastructure and the rare skills required are a significant cost in the long run.
Is it a fad? The question is not whether or not to go for it, but how do we go about it? And why? Without underestimating the complexity or an in-depth analysis of the actual requirements in terms of Volume, Velocity and Variety.
In many cases, BI will still be largely sufficient.

